Deadlock Patch Notes September 12: Unlocking System Stability
In the complex world of software and database systems, few issues are as disruptive and frustrating as a deadlock. It's a silent killer of performance, bringing operations to a grinding halt and often requiring manual intervention. For anyone managing critical applications, the release of significant updates addressing such issues is always met with keen interest. That's precisely why the "Deadlock Patch Notes September 12" have generated considerable buzz, promising crucial enhancements to system resilience and efficiency.
This comprehensive article delves into the intricacies of deadlocks, explores why they pose such a persistent challenge, and dissects the vital improvements delivered by the recent September 12 patch. We'll examine how these updates aim to mitigate the impact of deadlocks, enhance detection, and ultimately contribute to a more stable and reliable computing environment for all.
Table of Contents:
- What Exactly is a Deadlock?
- The Classic Deadlock Scenario Revisited
- Why Deadlocks Matter: Impact on System Performance
- Understanding the "September 12" Context: A Critical Update
- Key Features of the Deadlock Patch Notes September 12
- Implementing the Patch: Best Practices for Adoption
- Beyond the Patch: Continuous Deadlock Management
- Conclusion: A Step Towards Uninterrupted Operations
What Exactly is a Deadlock?
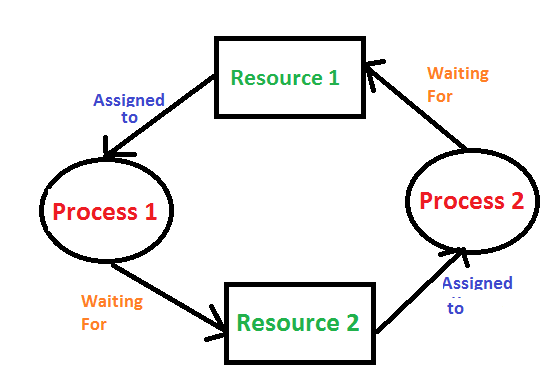
At its core, a deadlock represents a critical state within a system where processes or threads become perpetually stuck, unable to proceed because each is waiting for a resource held by another. As mentioned by others, a deadlock is typically the result of a situation where multiple entities are vying for limited resources in a specific, unfortunate sequence. Imagine a busy intersection where traffic lights fail, and cars from all four directions enter simultaneously, each blocking the path of another. No one can move, and the entire flow grinds to a halt. This analogy perfectly encapsulates the essence of a deadlock in a computing environment.
More formally, a deadlock is a state of a system in which no single process/thread is capable of executing an action. This occurs when processes are trying to get exclusive access to devices, files, locks, servers, or other resources. In the resource deadlock model, a process requests resources, uses them, and then releases them. Problems arise when multiple processes need access to the same resources concurrently.
For a deadlock to occur, four conditions, often referred to as the Coffman conditions, must simultaneously be met:
- Mutual Exclusion: At least one resource must be held in a non-sharable mode. Only one process can use the resource at any given time.
- Hold and Wait: A process holding at least one resource is waiting to acquire additional resources held by other processes.
- No Preemption: Resources cannot be forcibly taken from a process holding them. They must be released voluntarily by the process after it has completed its task.
- Circular Wait: A set of processes {P0, P1, ..., Pn} must exist such that P0 is waiting for a resource held by P1, P1 is waiting for a resource held by P2, ..., Pn-1 is waiting for a resource held by Pn, and Pn is waiting for a resource held by P0. This circular dependency is the signature of a deadlock.
Understanding these conditions is fundamental to grasping why deadlocks are so insidious and why the "Deadlock Patch Notes September 12" are so important for addressing them.
The Classic Deadlock Scenario Revisited
To truly appreciate the impact of the "Deadlock Patch Notes September 12," let's dive into the classic deadlock scenario. This is a common pattern observed in multi-threaded or multi-process environments, particularly in database systems or concurrent programming. The classic deadlock scenario is where process 'A' is holding lock 'X' and wants to acquire lock 'Y', while process 'B' is holding lock 'Y' and wants to acquire lock 'X'. Since neither can complete what they are trying to do, both processes are stuck indefinitely. This is a quintessential example of the circular wait condition in action.
A deadlock occurs when two threads each lock a different variable at the same time and then try to lock the variable that the other thread already locked. As a result, each thread is waiting for the other to release the resource it needs, leading to a standstill. For example, if threads T1 and T2 are involved:
- Thread T1 acquires Lock A.
- Thread T2 acquires Lock B.
- Thread T1 attempts to acquire Lock B (which is held by T2). T1 waits.
- Thread T2 attempts to acquire Lock A (which is held by T1). T2 waits.
Both threads are now blocking each other, unable to proceed. Usually, this has something to do with threads trying to acquire shared resources. This specific situation is often a program that purposely causes deadlock between two threads that are both trying to acquire locks for the same two resources. Developers must be acutely aware of such patterns to avoid this sort of deadlock when locking resources, and the September 12 patch notes likely offer new tools or strategies to prevent these common occurrences.
Why Deadlocks Matter: Impact on System Performance
The consequences of a deadlock extend far beyond a mere inconvenience; they can be catastrophic for system performance, data integrity, and user experience. When a deadlock occurs, the involved processes or threads cease to make progress, effectively consuming valuable system resources (CPU cycles, memory, network bandwidth) without producing any useful output. This leads to:
- System Unresponsiveness: Applications become sluggish or completely unresponsive, leading to frustrated users and potential loss of productivity.
- Resource Wastage: Resources held by deadlocked processes remain locked and unavailable to other legitimate processes, leading to resource starvation across the system.
- Data Inconsistency: In database systems, if a deadlock is not resolved gracefully, it can lead to transactions being partially completed or rolled back improperly, potentially leaving data in an inconsistent state. The system detects a deadlock while waiting for a resource, and rolls back one of the transactions involved in the deadlock, which is a common resolution mechanism, but it can still lead to lost work.
- Cascading Failures: A single deadlock can sometimes trigger a chain reaction, leading to more deadlocks or other system failures as dependent processes time out or crash.
- Operational Overhead: Identifying and resolving deadlocks often requires manual intervention from system administrators or developers, consuming valuable time and effort that could be spent on other critical tasks.
The economic impact can be significant, especially for businesses relying on real-time data processing, e-commerce platforms, or mission-critical applications. Downtime, even brief, translates directly to lost revenue, reputational damage, and decreased customer trust. This underscores the critical importance of robust deadlock prevention and resolution mechanisms, making the "Deadlock Patch Notes September 12" a highly anticipated and essential update for maintaining system health.
Understanding the "September 12" Context: A Critical Update
The release of the "Deadlock Patch Notes September 12" signifies a pivotal moment for system administrators, developers, and anyone invested in the stability of complex software environments. While the exact details of the system or application in question aren't specified, the very notion of a dedicated patch for deadlocks on a specific date implies a significant, targeted effort to address persistent or newly discovered vulnerabilities in concurrency management. This isn't just a routine bug fix; it's an acknowledgment that existing mechanisms might not be sufficient to handle the evolving demands and complexities of modern systems.
Why would such a patch be necessary now? Several factors could contribute to the timing of the "Deadlock Patch Notes September 12":
- Increased System Load: As applications scale and user bases grow, the sheer volume of concurrent operations increases, putting more strain on resource locking mechanisms and making deadlocks more frequent.
- New Concurrency Patterns: The adoption of new programming paradigms, frameworks, or database technologies might introduce novel ways for deadlocks to manifest, requiring updated detection and prevention logic. For instance, on my blog, I go into the details of how blocking in asynchronous code causes deadlock, highlighting how modern asynchronous patterns, while beneficial, can still lead to these issues if not carefully managed.
- Performance Bottlenecks: Even if deadlocks are rare, their impact can be severe. The patch might aim to reduce the time it takes for a system to detect a deadlock and initiate a rollback, thereby minimizing performance degradation.
- Security Implications: While less common, certain types of resource contention could potentially be exploited to cause denial-of-service attacks. A patch could address such vulnerabilities.
- Improved Diagnostics: Feedback from users and internal monitoring might have revealed shortcomings in existing deadlock diagnostic tools, prompting an update to provide better insights.
The "Deadlock Patch Notes September 12" represent a proactive step towards building more resilient systems. They acknowledge that while deadlocks cannot always be entirely eliminated, their frequency can be drastically reduced, and their impact can be managed more effectively. This commitment to stability is what makes these patch notes so significant.
Key Features of the Deadlock Patch Notes September 12
The "Deadlock Patch Notes September 12" are expected to introduce a suite of enhancements designed to tackle deadlocks from multiple angles: detection, prevention, and recovery. While specific technical details would vary depending on the system, we can infer the types of improvements that would be crucial for addressing such a pervasive issue.
Enhanced Detection and Diagnostics
One of the most critical aspects of managing deadlocks is the ability to quickly and accurately identify their occurrence. The September 12 patch notes likely detail significant improvements in this area. This could include:
- More Granular Lock Monitoring: Deeper insights into which resources are locked by which threads or processes, providing a clearer picture of resource contention.
- Faster Deadlock Graph Construction: Algorithms that can more rapidly build and analyze the resource allocation graph to detect circular waits. This means the system can identify a deadlock detected while waiting for a resource much sooner.
- Predictive Analysis: In some advanced systems, new heuristics might be introduced to predict potential deadlocks before they fully form, based on observed access patterns.
- Improved Alerting: More immediate and informative alerts when a deadlock is detected, including details about the involved processes and resources.
These enhancements are vital for troubleshooting. This way, you can have something in place to be able to troubleshoot any deadlock more effectively, providing the necessary data to understand the root cause.
Proactive Prevention Mechanisms
While detection is crucial, preventing deadlocks from occurring in the first place is the ultimate goal. The "Deadlock Patch Notes September 12" likely include features aimed at proactive prevention, building on established principles to avoid this sort of deadlock when locking resources. These might include:
- Ordered Resource Acquisition: New internal mechanisms or recommendations that enforce a strict order for acquiring multiple locks, thereby breaking the circular wait condition.
- Timeout Mechanisms: Enhanced or more configurable timeouts for resource acquisition. If a thread waits too long for a lock, it can abandon the attempt, releasing any locks it holds and retrying, thus preventing an indefinite wait.
- Deadlock Avoidance Algorithms: For certain contexts, the patch might introduce or refine algorithms (like Banker's Algorithm variants) that dynamically analyze resource requests to ensure that granting a request will not lead to an unsafe state where a deadlock is inevitable.
- Optimized Concurrency Control: Improvements to the underlying concurrency control mechanisms (e.g., in a database's transaction manager) to reduce contention points.
These preventive measures are designed to minimize the chances of a deadlock forming, improving overall system throughput and reliability.
Optimized Recovery and Rollback
Even with the best prevention, deadlocks can occasionally occur. When they do, efficient recovery is paramount to minimize disruption. The "Deadlock Patch Notes September 12" are expected to bring improvements to how the system handles recovery:
- Intelligent Victim Selection: When a deadlock is detected, the system typically rolls back one of the transactions involved in the deadlock. The patch might introduce more sophisticated algorithms for choosing the "victim" process to abort, minimizing the amount of work lost and the impact on other active transactions. For instance, it might prioritize rolling back the transaction with the least amount of work done or the one holding the fewest critical resources.
- Faster Rollback Execution: Improvements to the rollback process itself, ensuring that transactions are undone quickly and cleanly, releasing resources promptly.
- Graceful Error Handling: More robust error handling for applications when a transaction is rolled back due to a deadlock, allowing applications to retry operations gracefully.
The ability to recover quickly and cleanly is essential for maintaining system availability and data consistency, even in the face of unexpected contention.
Improved Logging and Troubleshooting
Finally, the "Deadlock Patch Notes September 12" would likely include significant enhancements to logging and diagnostic capabilities. This is crucial for developers and administrators to understand why deadlocks are occurring and to fine-tune their applications and configurations. Improvements might include:
- Detailed Deadlock Graphs in Logs: Exporting the full deadlock graph (showing which process holds which resource and which process waits for which) directly into logs for easier analysis.
- Performance Counters and Metrics: New performance counters specific to deadlock occurrences, detection times, and rollback events, allowing for better monitoring and trend analysis.
- Trace Flags and Debugging Tools: Introduction of new trace flags or enhanced debugging tools that can provide real-time insights into lock contention and potential deadlock situations.
- User-Friendly Reporting: Tools or scripts that can parse the new log data and present it in an easily digestible format. You will have to change the file path as appropriate for any provided code, but the improved output will make it a good idea to integrate these new diagnostic capabilities into existing monitoring frameworks.
These logging improvements are invaluable for ongoing system maintenance and for proactive identification of code patterns that contribute to deadlocks, allowing developers to refactor and optimize their applications.
Implementing the Patch: Best Practices for Adoption
While the "Deadlock Patch Notes September 12" offer significant benefits, their implementation requires careful planning and execution to avoid unintended disruptions. Adopting any critical system patch, especially one affecting core concurrency mechanisms, demands a disciplined approach. Here are some best practices for implementing this vital update:
- Review the Official Documentation: Thoroughly read the complete "Deadlock Patch Notes September 12" and any accompanying release guides. Pay close attention to prerequisites, known issues, and specific installation instructions.
- Backup Critical Systems: Before applying the patch, perform comprehensive backups of all affected databases, applications, and system configurations. This provides a crucial safety net for rollback if any unforeseen issues arise.
- Test in a Staging Environment: Never apply a critical patch directly to production without prior testing. Create a replica of your production environment (staging or UAT) and apply the patch there first. Simulate typical workloads, run regression tests, and specifically test scenarios known to cause deadlocks or high contention.
- Monitor Performance Closely: During and after patch application in the staging environment, monitor key performance indicators (KPIs) such as CPU utilization, memory usage, I/O rates, and, critically, deadlock frequency and resolution times. Look for any unexpected changes or new bottlenecks.
- Phased Rollout (if applicable): For large, complex systems, consider a phased rollout strategy in production. Start with a subset of less critical services or servers, monitor their stability, and then gradually expand the deployment.
- Communicate with Stakeholders: Inform relevant teams (development, operations, business users) about the patch schedule, potential impacts, and expected benefits. Ensure they are prepared for any brief downtime or performance fluctuations.
- Prepare a Rollback Plan: Despite thorough testing, issues can still emerge. Have a clearly defined and tested rollback plan in place, detailing the steps to revert to the previous stable state if the patch introduces critical problems.
By following these practices, organizations can maximize the benefits of the "Deadlock Patch Notes September 12" while minimizing risks, ensuring a smooth transition to a more stable and efficient system.
Beyond the Patch: Continuous Deadlock Management
While the "Deadlock Patch Notes September 12" represent a significant step forward in mitigating concurrency issues, it's crucial to understand that they are part of an ongoing journey, not a final destination. Deadlocks are inherent challenges in multi-threaded environments, and their effective management requires continuous vigilance and a multi-faceted approach. Relying solely on patches, no matter how comprehensive, is insufficient for long-term system health.
Beyond applying the latest "Deadlock Patch Notes September 12," organizations should integrate several continuous management strategies:
- Proactive Code Review: Developers should regularly review code for potential deadlock patterns, especially when dealing with shared resources, asynchronous operations where await will asynchronously wait until the task completes, and complex transaction logic. Implementing coding standards that promote consistent lock ordering can significantly reduce the likelihood of deadlocks.
- Performance Monitoring and Alerting: Implement robust monitoring tools that track lock contention, transaction timeouts, and actual deadlock occurrences. Configure alerts to notify operations teams immediately when thresholds are exceeded or deadlocks are detected.
- Capacity Planning: Ensure that systems have adequate resources (CPU, memory, I/O) to handle peak loads. Resource starvation can exacerbate contention and increase the frequency of deadlocks.
- Database Optimization: For database-centric applications, regularly review and optimize SQL queries, indexing strategies, and transaction isolation levels. Poorly written queries or inappropriate isolation levels can lead to excessive locking and increased deadlock potential.
- Architectural Design: Design systems with concurrency in mind from the outset. Consider using lock-free data structures, message queues, or microservices architectures to reduce shared state and minimize the need for complex locking mechanisms.
- Regular Training: Educate development and operations teams on the principles of concurrency, common deadlock scenarios, and best practices for prevention and troubleshooting.
- Post-Mortem Analysis: Whenever a deadlock occurs, even after applying the "Deadlock Patch Notes September 12," conduct a thorough post-mortem analysis to understand the root cause. Use the improved logging and diagnostic tools provided by the patch to gather detailed information and identify areas for further improvement in code or configuration.
By embracing these continuous management practices, organizations can build a resilient infrastructure that minimizes the impact of deadlocks, ensuring consistent performance and reliability for critical applications.
Conclusion: A Step Towards Uninterrupted Operations
The "Deadlock Patch Notes September 12" mark a significant milestone in the ongoing battle against one of the most persistent and disruptive issues in modern computing: the deadlock. We've explored how a deadlock, a state where no single process or thread is capable of executing an action, can bring systems to a standstill, leading to performance degradation, resource wastage, and potential data inconsistency. From the classic scenario where two processes are holding locks and waiting for each other, to the more complex interplay of asynchronous code, deadlocks pose a constant threat to system stability.
The enhancements introduced by the September 12 patch, particularly in areas like enhanced detection, proactive prevention, optimized recovery, and improved logging, promise to equip systems with more robust defenses against these insidious issues. By improving the ability to detect a deadlock while waiting for a resource and rolling back transactions more efficiently, these notes aim to minimize the impact when deadlocks do occur, and ideally, prevent them from forming in the first place. The focus on better troubleshooting tools also empowers administrators and developers to understand and address the underlying causes more effectively.
However, it's vital to remember that a patch, no matter how comprehensive, is just one component of a holistic strategy. Continuous vigilance, adherence to best practices in concurrent programming, robust monitoring, and a commitment to ongoing system optimization are all crucial elements in maintaining a truly stable and high-performing environment. The "Deadlock Patch Notes September 12" provide powerful new tools, but it is the diligent application and ongoing commitment of technical teams that will ultimately unlock uninterrupted operations.
What are your thoughts on these critical updates? Have you experienced significant improvements or challenges after applying the "Deadlock Patch Notes September 12" to your systems? Share your experiences and insights in the comments below. Your feedback helps the entire community navigate the complexities of concurrency management. And if you found this article insightful, consider sharing it with your colleagues or exploring other related content on our site for more deep dives into system performance and reliability.

Nerdly » ‘Deadlock’ Review
![Deadlock [Gameplay] - IGN](https://assets-prd.ignimgs.com/2024/08/29/deadlock-1724969546105.jpg)
Deadlock [Gameplay] - IGN
Introduction of Deadlock in Operating System - GeeksforGeeks
